
Article Title: Bayesian modeling of human–AI complementarity
Authors & Year: M. Steyvers, H. Tejeda, G. Kerrigan, and P. Smyth (2022)
Journal: Proceedings of the National Academy of Sciences of the United States of America [DOI:10.1073/pnas.2111547119]
Review Prepared by David Han
Exploration of Human-Machine Complementarity with CNN
In recent years, artificial intelligence (AI) and machine learning (ML), especially deep learning, have advanced significantly for tasks like computer vision and speech recognition. Despite their high accuracy, these systems can still have weaknesses, especially in tasks like image and text classification. This has led to interest in hybrid systems where AI and humans collaborate, focusing on a more human-centered approach to AI design. Studies show humans and machines have complementary strengths, prompting the development of frameworks and platforms for their collaboration. To explore this further, the authors of the paper developed a Bayesian model for image classification tasks, analyzing predictions from both humans and convolutional neural networks (CNN). The Bayesian model is a statistical approach that updates knowledge/beliefs based on evidence, combining prior knowledge with new information to make better predictions or decisions. CNN, used in image processing, are similar to how humans view things but they make mistakes in different ways from humans, making them ideal for studying human-machine complementarity (viz., the synergy and cooperation between humans and machines). This model helps explore conditions for complementarity, such as when to combine predictions from humans and machines, or from groups of humans or machine algorithms. It also helps in understanding how to combine and differentiate errors made by both, as well as integrate their different confidence levels.
Bayesian Combination of Human & Machine Classifier Predictions
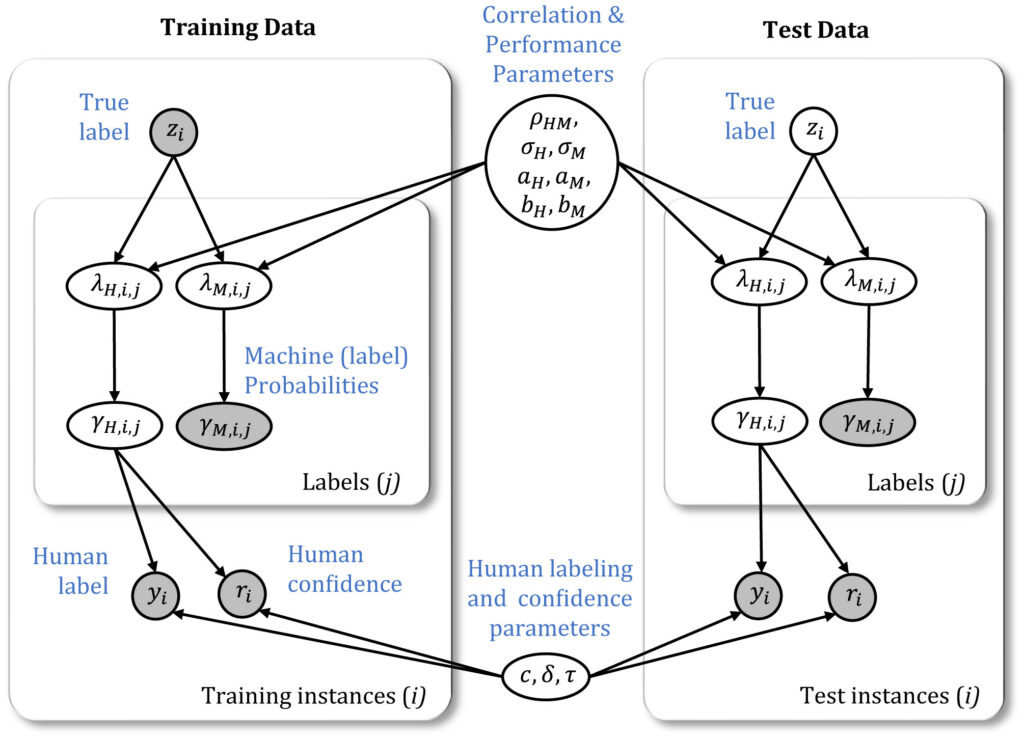
The proposed Bayesian model combines classifications and confidence scores from different types of classifiers: human or machine. It focuses on three pairs: hybrid human-machine (HM), human-human (HH), and machine-machine (MM). This model produces combined predictions and estimates correlations between classifiers, capturing how their confidence scores relate. For instance, if one classifier is confident about a label, another might show similar confidence. Unlike previous models, which assume no association between the classifiers, this model accounts for varying confidence score types. Machine classifiers give probability distributions, while humans provide single ordinal responses (like “low,” “medium,” and “high”). The process starts with a probability-based model, generating human and machine logit scores for each label. These are then transformed into probability confidence scores. For machine classifiers, confidence scores are observed directly while they are indirect for human classifiers. The model uses known ground truth labels for training data and unknown labels for test data. It considers observed human labels, confidences, and classifier probabilities for both training and test sets. Figure 1 illustrates the graphical model for combining hybrid HM pairs. Using Markov Chain Monte Carlo (MCMC) methods, the model parameters are estimated from observed data, and the probability distribution is updated (i.e., the posterior distribution).
Complementarity of Human & Machine Classifiers
For this study, the authors gathered human and machine classification decisions over 4,800 images. Using various CNN architectures known for high accuracy, they also introduced variability in machine classifier performance. In Figure 2A, humans struggle but machines excel, with low human accuracy and confidence compared to high machine accuracy. Figure 2B shows the reverse: humans succeed while machines struggle. This highlights the complementarity between humans and machines, each performing better in different situations.
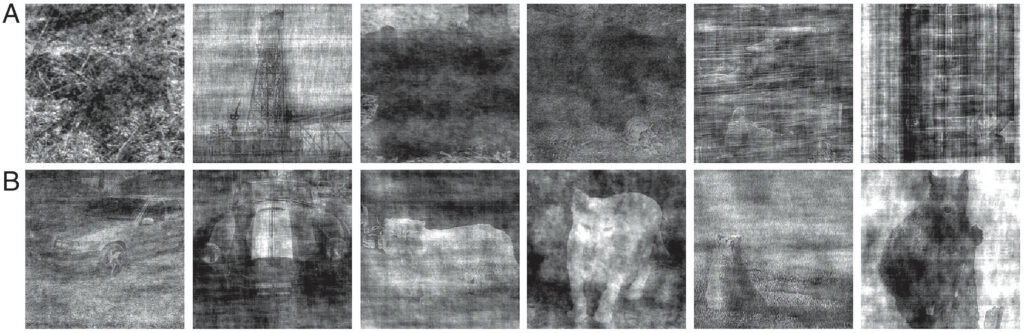
A) Images that pose challenges for humans but relatively easy for machine classifiers. The correct classifications are bird, boat, bear, bear, oven, and oven;
B) Images that are difficult for machine classifiers but easier for humans. The correct classifications are car, car, cat, cat, bear, and bear.
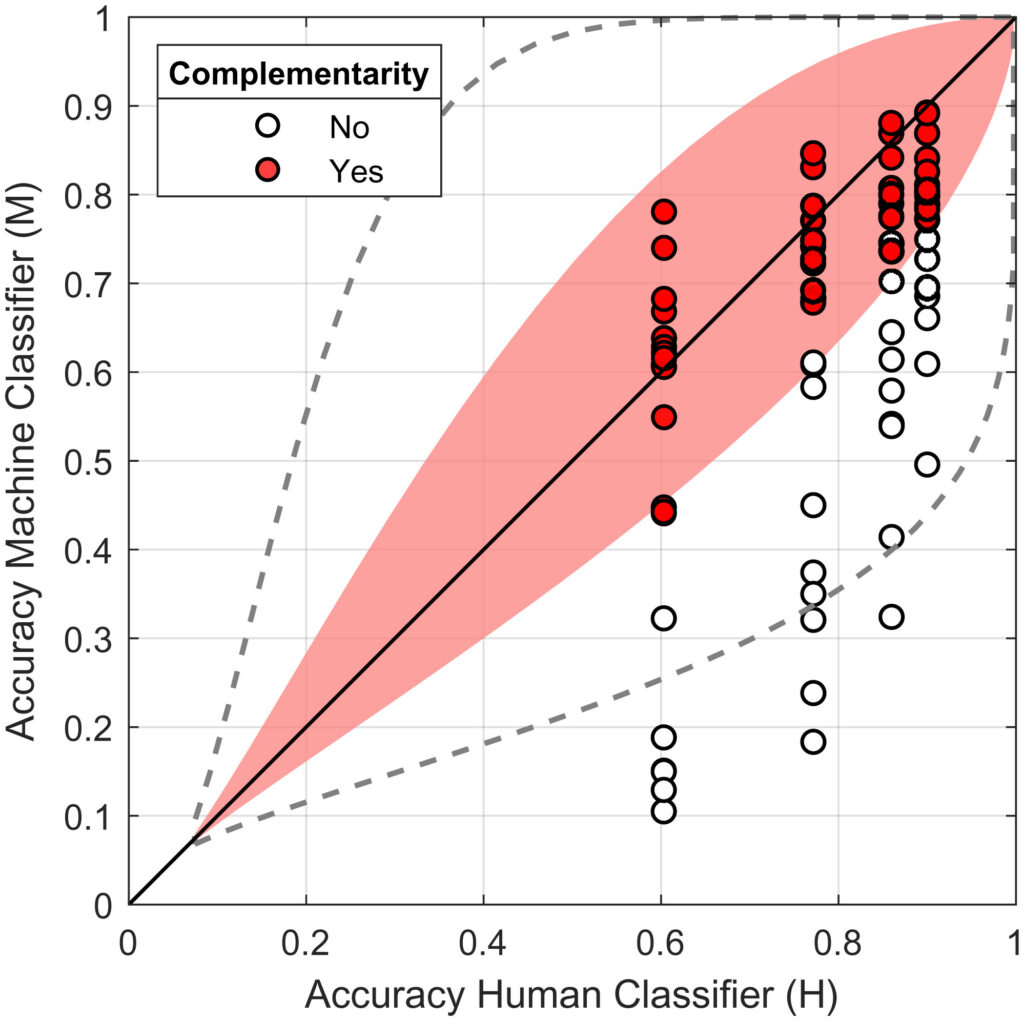
Figure 3A shows how well the model performs on new data after just a little more training on CNN. The findings show that HM pairs perform well, especially with high noise, although Alexnet’s low baseline performance limits complementarity with humans. Combining two humans generally outperforms a single human, emphasizing the use of human confidence scores to improve accuracy. Figure 3B shows that when humans and machines work together (i.e., hybrid combinations of human and machine classifiers), the correlations between their predictions are less strong compared to when humans or machines work alone. Another important finding is that complementarity between human and machine classifiers depends on their differences in accuracy. Figure 4 illustrates this, showing observed and predicted complementarity outcomes for hybrid pairs. It displays results for 320 comparisons across image noise levels and fine-tuning (a procedure to adjust a pre-trained model to boost the task-specific performance). The shaded region indicates the narrow range where complementarity occurs, influenced by correlations between classifiers. If the HM pair has zero correlation, the complementarity zone expands (dashed line) since the human-machine performances can be augmented creating the synergy. Nevertheless, there are still limits on the accuracy differences for complementarity.
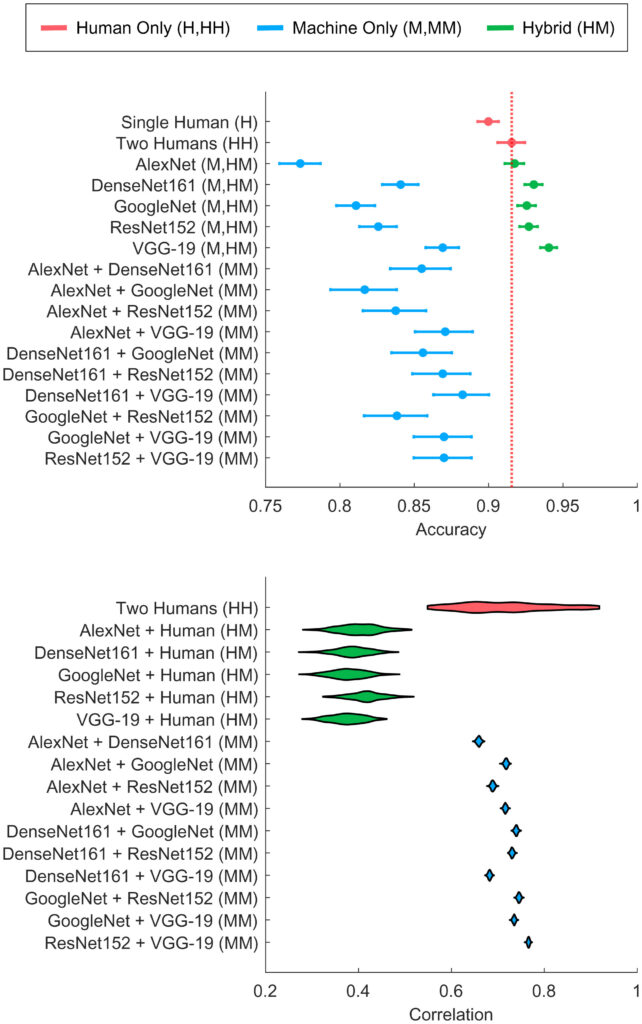
Bottom: Posterior distributions over correlations from the Bayesian combination model
Importance of Designing Collaborative Human-AI Systems
The study finds that the following factors are statistically significant to improve the performance of the hybrid HM pairs, especially in high-noise conditions:
- A customized error model that corrects errors and biases from both human and machine classifiers for specific labels
- Human confidence scores
- Machine classifier scores
Machine confidence scores have a larger impact on performance than human confidence scores or an error model. This is because machine classifiers provide scores across all labels simultaneously, while humans offer a single confidence score for their decision. Human confidence ratings and the error model contribute similarly to hybrid performance. Thus, one way to boost hybrid HM classifier performance is by including human confidence ratings. These findings emphasize the importance of confidence scores from both human and machine classifiers in hybrid classifier performance. The findings also show that combining predictions from a single human with those of a machine can improve performance, even when the human outperforms the machine. Conversely, a hybrid HM pair can outperform combinations of machine classifiers that individually outperform a single human. This has implications for algorithms not yet at human-level accuracy. Adding less accurate algorithmic predictions to a human predictor can improve performance more than adding additional human predictions. The benchmark for AI algorithms need not always be human-level; even below-human-level algorithms can enhance accuracy in hybrid predictions. This research highlights the potential benefits of combining human and AI predictions, even when AI falls short of human-level performance. It suggests that effective AI systems don’t need human-level accuracy to improve outcomes, and human judgment remains valuable. However, there are limits to complementarity. An important factor is the correlation between human and machine classifier predictions, setting limits on the accuracy difference that supports complementarity; see Figures 3 and 4. This suggests that effective AI advice should strive for independence from human judgment so that the human-machine synergy can be truly realized with meaningful performance enhancement when humans and machines work together. Human confidence scores play an important role, enhancing hybrid performance similar to an explicit error model. This study provides a framework for evaluating hybrid human-machine predictions, relevant for domains like medicine and the justice system. For example in the justice system, machine could analyze large amounts of legal data to identify patterns and trends while human experts could provide contextual understanding and moral reasoning. This combination could lead to more informed and fairer decisions in areas such as case evaluations, sentencing, and parole determinations, potentially reducing biases and errors inherent in human judgment alone.
![Flow chart showing the steps of the LLM approach for clinical prdeiction. The top left is part a with a Lagone EHR box connected to 2 boxes, NYU Notes(clinical notes) and NYU Fine-Tuning (clinical notes and task specific labels). The top right is the pret-training section with NYU notes (clinical notes) in the far top right connected to a language model box which then connects to a larger masked language model box below it (fill in [mask]: a 39-year-old [mask] was brough in by patient (image representing llm replying) patient)). The bottom left has nyu fine tuning (clinical notes and task specific tasks) in the top right of its quadrant connected to a pretrained model box which connects down to a larger fine-tuning box, specifically the predicted p(label) ground truth pair (0.6, 0.4) which connects to a small box inside the big on lageled loss which goes to another small box labeled weight update which goes back to the pretrained model box. The last quadrant in the bottom right has two boxes on the left of fine-tuned model and hospital ehr(clinical notes) connected to inference engine in the top right of the quadrant that connects down to the email alert (physician) box](https://mathstatbites.org/wp-content/uploads/apollo13_images/msbHanNyu1-7ipft2sfku393xh5nv4pp16roldxrt3aay.png)