
Title: Causal Inference for Social Network Data
Author(s) and Year: Elizabeth L. Ogburn, Oleg Sofrygin, Iván Díaz, Mark J. van der Laan, 2022
Journal: Journal of the American Statistical Association, open access: https://doi.org/10.1080/01621459.2022.2131557
“If all of your friends jumped off a cliff, would you jump too?” While this comeback may be just an annoying retort to many teenagers, it presents an interesting question – what is the effect of social influence? This is what Ogburn, Sofrygin, Diaz, and van der Laan explore in their paper, “Causal Inference for Social Network Data”. More specifically, they are interested in developing methods to estimate causal effects in social networks and applying this to data from the Framingham Heart Study.
Causal inference has been covered on MathStatBites before – check out Brian’s blog post for a great introduction. In summary, causal inference is a branch of statistics that aims to characterize the effects of a treatment on an outcome (not just correlations). This is of interest in many applications – for example, a sociologist may be interested in whether an educational program for fifth graders (the treatment) causes an improvement in test scores (the outcome). A lot of causal inference work focuses on relatively simple set ups where the individuals are assumed to be not highly dependent. But many researchers, including Ogburn et al., are currently working on methods for more complicated scenarios.
The complexities of this set up come from the “social network data”. A social network can be thought of as a visualization of a community. In their paper, Ogburn et al. use the Framingham Heart Study as an illustration. The Framingham Heart Study is a longitudinal study that collected health and social connections data on 15,000 individuals from the town of Framingham, Massachusetts, and adjacent towns. This data was collected via medical examinations and written questionnaires completed at regular intervals.
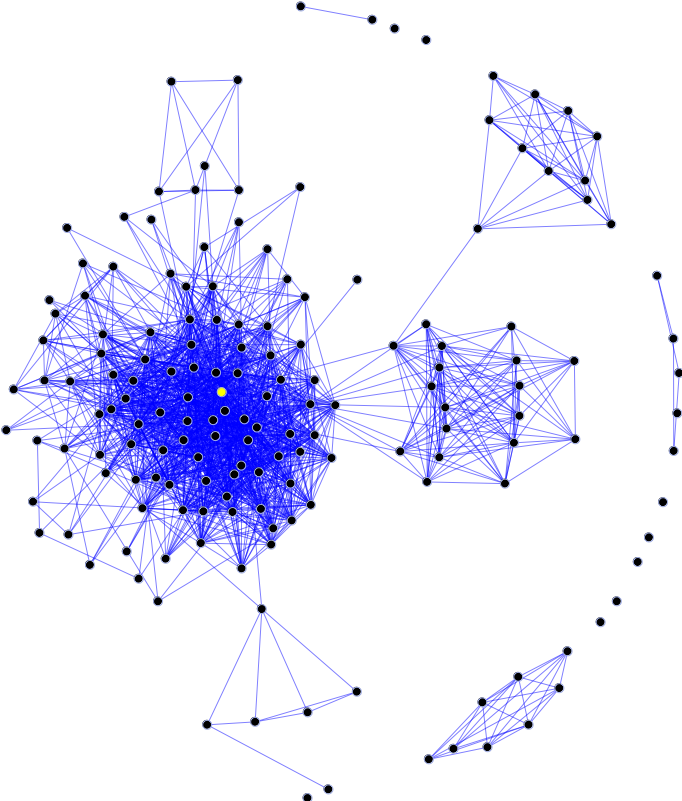
Fig 1. This is an example of a social network. Dots are called nodes and lines connecting two nodes are called edges. For the Framingham Heart Study network, two nodes have an edge between them if the corresponding people have any type of direct social connection, e.g. siblings, spouses, or immediate neighbors. By Screenshot taken by User:DarwinPeacock – Screenshot of free software GUESS, CC BY 3.0, https://commons.wikimedia.org/w/index.php?curid=6057981
Each person represents a node in the network, and two nodes have an edge between them if they are related in some way. For the Framingham Heart Study network, two nodes have an edge between them if the corresponding people have any type of direct social connection, e.g. siblings, spouses, close friend, or immediate neighbors.
For causal inference in this setting, researchers may be interested in estimating peer effects, the effect of one subject’s outcome on the future outcomes of their peers. In their example, the authors were interested in estimating the peer effects of obesity, i.e. is obesity “socially contagious”?
As mentioned previously, many other causal inference methods assume that the individuals are not highly dependent. However, that is not the case here. We have dependence due to the connections between individuals because information can travel along these connections. In addition, we have dependence due to a phenomenon called homophily – the tendency of like-minded people to have connections. In other words, people with ties in the network are likely to have underlying similarities that can also affect their outcomes.
Recall that in their Framingham Heart Study example, the authors were interested in studying whether obesity is “socially contagious”. Previous work done by Christakis and Fowler found that it is. Depending on the relationship type, the increased risk of obesity ranged from 27% to 171%. However, one assumption of their analysis is that the occurrence of each network edge is independent. In other words, they do not properly consider dependencies from the full network structure, such as homophily.
In contrast, the authors’ method does consider the full network structure. To assess the peer effects, the authors considered a hypothetical scenario where each subject was given an additional peer who was obese – this is the treatment. Then, they checked whether this would increase the probability of the subject becoming obese in the future – this is the outcome. Ultimately, they found that the answer was no, supporting the claim that obesity is not “socially contagious”.
This contrary result suggests that the results from Christakis and Fowler could be attributed to a mismatch between the data and their assumptions. This comparison highlights how results can become invalid when the assumptions of the methods do not match what is seen in the data.
Of course, no method is clear of assumptions. One major assumption of this method is that we can observe the full social network. This is important because if we are missing part of the network, we may miss features that could affect the results. An additional assumption is that if two subjects do not have a connection, they act independently of each other. In some cases, this is fine, but it is not always reasonable.
In the paper, the authors give a more comprehensive explanation of how they estimate causal effects, as well as some nice mathematical properties of the estimators. However, it is quite complex, so I won’t be covering it in this blog post. (If that piques your interest, I’d encourage you to check out the paper!). Overall, this method marks a step forward in estimating causal effects from social networks. Ogburn et al. were able to incorporate two types of dependencies seen in social network data which, when not properly accounted for, have the potential to invalidate results. This method could be especially useful in other applications, such as studying misinformation in social media networks or theories in international relations. And you may even want to use it to estimate the chances of you jumping off a cliff if your friends jump off first.
References:
Christakis NA, Fowler JH. The spread of obesity in a large social network over 32 years. N Engl J Med. 2007 Jul 26;357(4):370-9. doi: 10.1056/NEJMsa066082. Epub 2007 Jul 25. PMID: 17652652.