
Title: Dynamic Causal Effects Evaluation in A/B Testing with a Reinforcement Learning Framework
Authors and Year: Chengchun Shi, Xiaoyu Wang, Shikai Luo, Hongtu Zhu, Jieping Ye, Rui Song (2022)
Journal: Journal of the American Statistical Association, Theory and Methods (DOI: 10.1080/01621459.2022.2027776)
Companies often want to test the impact of one design decision over another, for example Google might want to compare the current ranking of search results (version A) with an alternative ranking (version B) and evaluate how the modification would affect users’ decisions and click behavior. An experiment to determine this impact on users is known as an A/B test, and many methods have been designed to measure the ‘treatment’ effect of the proposed change. However, these classical methods typically assume that changing one person’s treatment will not affect others (known as the Stable Unit Treatment Value Assumption or SUTVA). In the Google example, this is typically a valid assumption—showing one user different search results shouldn’t impact another user’s click behavior. But in some situations, SUTVA is violated, and new methods must be introduced to properly measure the effect of design changes.
One such situation is that of ridesharing companies (Uber, Lyft, etc.) and how they determine which drivers are sent to which riders (the dispatch problem). Simply put, when a driver is assigned to a rider, this decision impacts the spatial distribution of drivers in the future. Hence the dispatch strategy (our treatment) at the present time will influence riders and drivers in the future, which violates SUTVA and hence invalidates many traditional methods for A/B testing. To tackle this problem, a group of researchers have recently employed a reinforcement learning (RL) framework which can accurately measure the treatment effect in such a scenario. Furthermore, their proposed approach allows for companies to terminate A/B tests earlier if the proposed version B is found to be clearly better. This early stopping can save time and money.
To better understand RL and how it can contribute to tackling the issue at hand, it’s first helpful to set some context. In typical RL problems, including the one in this paper, the scenario is modeled with something known as a Markov Decision Process (MDP). A MDP links three sets of variables across time: the state or environment, the treatment or action (the reaction to the environment), and the outcome (the response produced by the environment due to the action). These outcomes can be thought of as rewards which depend on the action taken and the state observed. Over time, the machine learns which actions produce more positive rewards and which bring about worse outcomes. Hence, the actions leading to higher rewards are positively reinforced, thus the name reinforcement learning. A causal diagram of an MDP is shown in Figure 1, where St, At, and Yt are the state, action, and outcome at time t. As one can see, past treatments influence future outcomes by altering the state variables at the present (the so-called “carryover effect” which violates SUTVA).
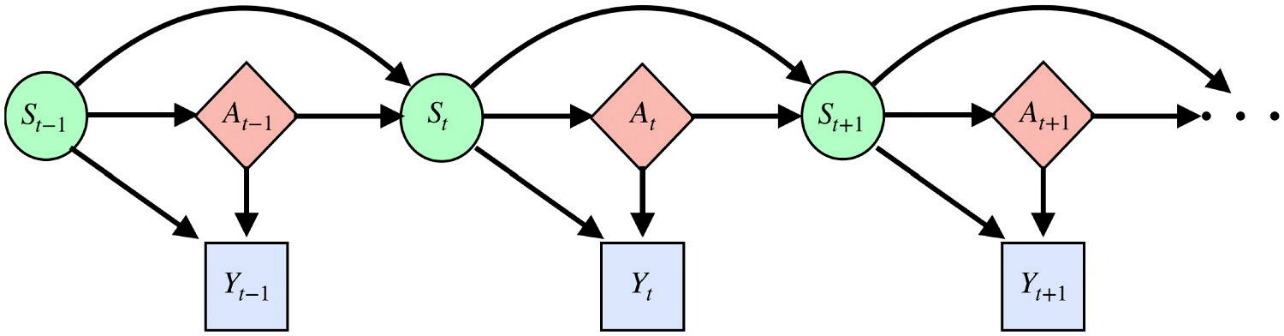
Figure 1: Causal Diagram of MDP, where the solid lines represent causal relationships
Making this more concrete, consider an example where the decision-maker is a ridesharing company. The environment or state is whatever variables the decision-maker can measure about the world, like the spatial distribution of drivers, number of pickup requests, traffic, and weather. The company then makes some action on how to dispatch drivers. The combination of the state and action leads to an outcome that can be measured, for example passenger waiting time or driver’s income. The strategy which is used to determine an action is known as a policy. This policy could be designed to take the state into account or simply be fixed regardless of what environment is encountered. Much of the reinforcement learning literature focuses on the former (policies that depend on the state), but the authors argue that fixed designs are the de facto approach in industry A/B testing and hence they focus on that setting. In particular, a common treatment allocation design is the switchback design, where there are two policies of interest (the current dispatching strategy vs a proposed strategy) determined ahead of time and they are employed in alternating time intervals during the A/B test.
So how are policies compared to determine the treatment effect? The answer lies in what is known as the value function, which measures the total outcome that would have amassed had the decision-maker followed a given policy. The value function can put more value on short-term gain in outcome or long-term benefits. The two policies in an A/B test each have their own value functions, and a proposed policy is determined to be better if its value is (statistically) significantly higher. In the ridesharing setting, one possible outcome of interest is driver income. An A/B test in that scenario would thus look to see if a proposed policy had greater expected driver income vs the current policy.
A natural question is when to end the experiment and test for a difference in value. In practice, companies will often simply run the test for a prespecified amount of time, such as two weeks, and then perform an analysis. But if one policy is clearly better than another, that difference could be detectable much earlier and the company is wasting valuable resources by continuing the experiment. To address this issue, the authors take an idea from clinical trials, the ‘alpha-spending’ approach, and adapt it to their framework. Alpha-spending is one way to distribute over time the prespecified ‘budget’ of Type 1 error (the probability of falsely detecting that a new policy is better). In the article’s real-data example, the authors test once a day for each day after one week and are able to detect a significant difference on Day 12. Waiting until Day 14 would have resulted in poorer outcomes since a suboptimal policy would be implemented half the time for two more days.
Overall, the framework introduced allows for handling of carryover effects, is capable of modeling treatment allocation like the switchback design, and furthermore, allows for possible early stopping. With these three features, the authors argue their approach is highly applicable to the current practice of ridesharing companies (and possibly other industries as well). For interested readers wanting to dive deeper into the methodology presented, you can check out the full article, listen to the first author discuss the material at the Online Causal Inference Seminar, or explore the Python implementation available on Github.