
Title: Breaking the Winner’s Curse in Mendelian Randomization: Rerandomized Inverse Variance Weighted Estimator
Authors and Year: Xinwei Ma, Jingshen Wang, Cong Wu; 2023
Journal: Annals of StatisticsReview Prepared by Mackenzie Simper
Does a higher body mass index (BMI) increase the severity of COVID-19 symptoms? Mendelian randomization is one method that can be used to study this question without worrying about unmeasured variables (e.g., weight, height, or sex) that could affect the results. A recent paper published in the Annals of Statistics developed a new technique for Mendelian randomization which improves the ability to measure cause-and-effect relationships.
Understanding Cause and Effect
How can we measure the effects of one variable X, called the exposure variable, on another variable Y, called the outcome variable? The gold-standard in statistics would be to utilize a randomized control trial (RCT). In an ideal RCT, participants are randomly assigned to an exposure group and a control group. Randomization ensures the two groups are roughly equal in all characteristics that might be relevant to both the exposure and outcome variable, e.g., sex, height, weight, and so on. These characteristics are called confounding variables. Controlling for confounding variables ensures that any measured effect is actually due to the exposure variable.
In practice, an RCT may not be feasible or ethical. It’s impossible to randomly assign people to different BMIs. If we divided a sample of adults into two groups based on BMI, these groups would not be random, and thus wouldn’t be accounting for other variables that could influence both BMI and COVID-19 severity (such as use of alcohol or cholesterol levels). We could try to select participants to balance the groups for these variables, but it would be nearly impossible to measure and account for all the possible confounders.
Mendelian Randomization
What if we could find a variable, say Z, that caused only X, but was not impacted by any confounding variables? Then the association between Z and Y would essentially be the association between X and Y (see Figure 1). In Mendelian randomization (MR), Z is a set of genetic variants: changes in DNA which are shared among some individuals. Named after the 19th century biologist and mathematician Gregor Mendel, who first described genetic inheritance, the key idea in MR is that genes are randomly inherited and not affected by external factors. MR is called “nature’s randomized control trial” because it is natural genetic inheritance which assigns individuals to the exposure or control group.
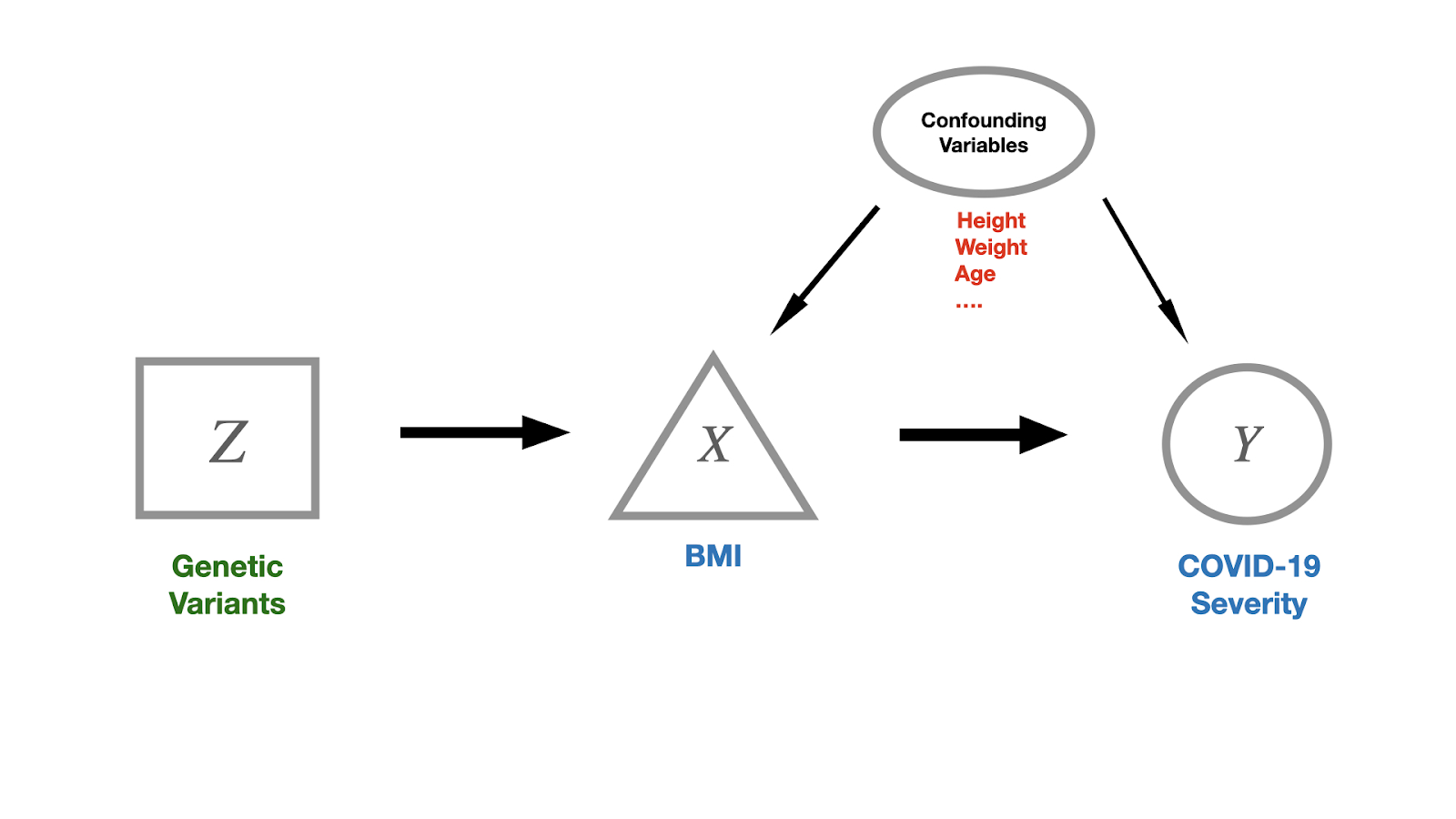
Figure 1: Schematic of cause-and-effect relationships in Mendelian Randomization.
The Winner’s Curse
How do we select the genetic variants that are associated with the exposure? The standard practice is to use a GWAS (Genome-Wide Association Study), which measures the association of all possible genomic variants with the exposure variable. The subset of variants with a strong association are selected and included in the MR study.
The Winner’s Curse arises when the same sample is used for the GWAS and for the next step of MR. The measured association from GWAS is a random variable – it can change depending on the sample. Since we’re choosing variants with associations greater than some arbitrary cut-off, there is a tendency to overestimate the true association. This can lead to an underestimate of the causal effect of the variant on the outcome variable, purely because the variant was not strongly associated with the exposure in the first place.
One solution to this problem is to use a different dataset for GWAS, but it is often difficult to find a third independent genetic dataset. To make the best use of all available data, the authors developed a new method which does not require an independent dataset.
To break the Winner’s Curse, the proposed solution utilizes two key ideas:
- Randomized variant selection: Add some randomness to the measured association of each variant and then select the variants which have an association larger than some cut-off value. Variants already with a large association will be unaffected, but it may change acceptance/rejection for variants which were on the line of the cut-off.
- A new estimator: In statistics, an estimator is a function of the data which is used to infer the value of an unknown parameter from a sample. For example, the parameter we want to study could be the average height in the population, and our estimator is the average height from a random sample. In the case of MR, the unknown parameter is the effect of the exposure on the outcome variable. The authors propose a new estimator which helps correct for the measurement bias which comes from the fact that the GWAS association is still just an estimate. It’s as if we first approximate the measuring stick and then use the estimated measuring stick to find the height of our samples – the first step results in measurement bias which can skew the final results if it’s not accounted for.
These two steps combine to create the Rerandomized Inverse Variance Weighted Estimator (RIVWE), named because the first step “rerandomized” the variant selection (which was already random due to the random inheritance of genes). The authors prove theoretical guarantees for the RIVWE estimator, which means that under ideal conditions it does exactly what they want it to.
To test their method on real data, the authors first tried a same trait analysis, where the same trait is used as both the exposure and outcome variables. If X = BMI and Y = BMI, then of course X should strongly cause Y! This type of study serves as a baseline check that the new MR method is performing as expected. For X = BMI and Y = COVID-19 severity, the new method finds an even larger causal effect than previous results.
Conclusion
Mendelian randomization is a powerful tool to investigate cause-and-effect relationships between variables when traditional randomized control trials are not practical. The development of the RIVWE method is a significant step toward more accurate and reliable results in this field, which can be used to help understand complex relationships, like BMI and COVID-19 severity. By breaking the Winner’s Curse, researchers can confidently explore the causal relationships between various traits and health outcomes.