
To John, enticements never can exert a pull. Probably the product of a disciplined upbringing. When John wants to buy something, he knows exactly what he’s looking for. He gets in and he gets out. No dilly-dallying, no pointless scrolling. Few of us are like John; the rest secretly aspire to be. Go on. Admit it! The science of enticing customers is sustained by this weakness. Take a reckless plunge into memory. Many’s the time when, based on what you bought, you were nudged into buying another item that “goes with it”. You may have a vague sense of how this works: what goes with what is probably established through history – people empirically tend to buy these items together. Intricacies around these recommendations, such as the order in which you add items, how personalized these recommendations are, whether the duration between your trips makes a difference, etc., may remain matters of mystery. Sophisticated algorithms are deployed to deal with such subtleties with varying degrees of success. The value of tracking one’s “demand evolution”, a notion that Wang and others have introduced in their work “Modeling user demand evolution for next-basket prediction” is in shedding light on these nuances through much more ordinary tools – mere historical frequencies that you already suspected – so that even you, with far less resources (and machines, if need be), can figure out and tinker with the internal mechanics in a way that is explainable. Suggestion-making won’t stay an algorithmic monopoly.
A shopping spree interrupted. Or was it accelerated?
John is pushing his trolley (actual or virtual) through a supermarket. And he bumps into somebody. Based on what’s already in John’s trolley, would this other person be able to foresee what he’s going for next? The answer, and more crucially, the way of getting there hinges vitally on this other person. If it’s a close friend who knows John is the stubborn John that he always is, the answer may be of one kind – pretty predictable with John because of his loyalty to certain items. If it’s a random stranger who isn’t quite aware yet of John’s stubbornness, the answer may be of a different kind – still predictable, but of a different sort: based on what “normal” people generally buy next. Research exploring this second possibility uses such concepts as complementarity and lift. Please check this brief post [2] for a quick introduction to some of these crucial tools. Prudent recommendation systems, however, remain mindful of both possibilities. It is within the first that the current work rests, although, as we will see later, some of it may be transferred even to the second.
Enter EvoDESA! Enter demand satisfaction! The crux of thematic dissonance
The authors begin by noting that a buyer’s demand for an item fluctuates depending on the type of item demanded. Food, for instance, is demanded more frequently than clothes. Exploiting a steady record of a specific buyer’s – say John’s – market baskets {𝐵1, 𝐵2, …, 𝐵𝑡−1},the authors develop a way to guess John’s

Figure 1: The EvoDESA architecture. Within the first module, we look at the demand estimation arm, using information from previous baskets. The second module helps figure out items that best satisfy a buyer’s demand.
demand – for several items: clothes, food, and more – at the next point in time, i.e., when he is putting items in his t-th basket 𝐵𝑡 (please see Figure 1). The recommended way is by multiplying with ℎ𝑗−1 – John’s demand state (𝑗 − 1) – a function 𝑓 (𝑔𝑗) that represents the way the effect of the (𝑗 − 1)-th basket wears off. An exponential decay
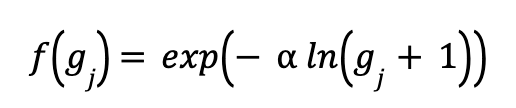
was used for simulation purposes. Here 𝑔𝑗 represents the gap between the (𝑗 − 1)-th and the 𝑗-th basket. The higher the or the more the gap, the more the effect wears off during the “demand generation stage” – the period between two successive trips to the store, leading to an elevated demand for that item on the following visit. The best value for can be guessed through a cross validation. Different α’s may be needed for different items: a higher value for food, a lower one for clothes, for example. Once every item is accounted for, a grand demand state ℎ𝑗 is generated for the next trip by concatenating, that is placing side by side, these individual sub-demands. “Evolving Demand Satisfaction” or the EvoDESA model in short – the fresh tool the authors put forth, runs in two steps. Estimating the next demand state as shown above is the first. The next has to do with the satisfaction bit.
If 𝐵𝑡’s size is K, this stage fills 𝐵𝑡 with K items in K steps. In the k-th (1 ≤ k ≤ K) step, we take each of the available candidate items (food, clothes, etc.) to update – using the first demand estimation algorithm – the user’s demand state ℎ𝑡𝑘−1 to ℎ𝑡𝑘 respectively. Then, a corresponding numerical satisfaction score 𝑠𝑡𝑘 is calculated to quantify the degree to which a user’s demand is satisfied in such a state:
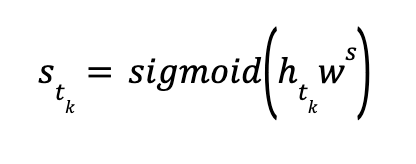
where 𝑤𝑠 ∈ 𝑅 dim𝑑𝑖𝑚 ( ℎ𝑡𝑘 ) 𝑥1 is a learnable score weight vector. 𝑠𝑡𝑘 ∈(0, 1) and a larger value indicates better satisfaction of the user’s demand. This second stage selects the candidate item that generates the maximum satisfaction score as the k-th item to be added into basket. That’s EvoDESA’s recommendation!
The fluctuating demands of recommending: EvoDESA’s place in all that
The stranger that John bumped into may peer into his trolley, notice he got cornflakes already and guess, using basket complementarity-triggered automacy (again, the brief post [2] elaborates more), John’s heading next to the milk aisle. Or the other way around. An algorithm may use the same strategy to show John certain products under the “frequently bought together” heading. Notice, however, in case an algorithm had been tracking John, summarizing his previous trips, we can paint a profile for John and make inferences based on his specific – probably idiosyncratic – buying habits. We can see how John is quite loyal to milk, cornflakes, bread and butter, buying some of these on almost every trip. Also, maybe lately, he has been developing a weakness for organic foods. These items are gradually becoming compatible with John. Having such a detailed history on John would not be easy, though. We need to solicit help either from one of his friends (the first scenario we were discussing towards the beginning) or an algorithm that had been tracking John. We settle, frequently, for a compromise, with some receipts from returning customers, others from fresh ones. And good recommendations work on this three-pronged (complementarity-compatibility-loyalty) system (Wan et al. (2018) is a stunning resource with certain machine learning tools) offering both blanket recommendations for typical buyers and also tailored ones targeted to specific people. It is the last two of these jobs that EvoDESA, through highlighting the disjunct between two neighboring baskets – the influencer and the influenced, helps us tackle.
In conclusion
A large part of the world we inhabit, the economy we form, functions through enticements. Whether we know it or not, whether we like it or not, as our society becomes increasingly connected, we mainly shuttle between recommendations. From algorithms, from friends, from our past experiences. You reading this very piece, after all, could be the effect of a recommendation. You may have been nudged to this through keyword-matching, because of your reading habits, because of another similar one you read. Whatever the intention behind these recommendations – be it persuading you to buy one more item, be it genuinely reminding you of a related product you may have forgotten while grocery-shopping, the key difficulty is in knowing which items are functionally or thematically entangled. How your need for a certain item varies with the passage of time, with the presence of some others in your basket. The authors deliver an answer, and, for its generalization, a firm blueprint. The item that maximizes your estimated demand satisfaction is the one to suggest.
Every time we gravitate towards a shiny distraction, every instant we give in to gratuitous buying advice, every moment we are unable to stay unswayed may remain witness to EvoDESA’s deft devotion to our downfall. Here’s to great recommending!
References:
[1] Wang. S., et al. (2022). “Modeling User Demand Evolution for Next-basket Prediction,” in IEEE Transactions on Knowledge and Data Engineering, doi: 10.1109/TKDE.2022.3231018.
[2] Bhaduri, M. (2023). “Using ‘basket complementarity’ to make product recommendations.” Real World Data Science, March 2, 2023. https://realworlddatascience.net/ideas/datasciencebites/posts/2023/03/02/basket-complementarity.html
[3] Wan, M., Wang, D., Liu, J., Bennett, P.N., McAuley, J. (2018). “Representing and recommending shopping baskets with complementarity, compatibility, and loyalty”. https://cseweb.ucsd.edu/~jmcauley/pdfs/cikm18a.pdf