
Beyond the Numbers – Why Causal Inference Needs More Than Statistics
Title: Causal Inference Is Not Just a Statistics ProblemAuthors & Year: McGowan, L.D., Gerke, T., and Barrett, M. (2024)Journal: Journal of Statistics and Data Science Education [DOI: 10.1080/26939169.2023. 2276446]Review Prepared by David Han Causality Is Not Obvious, Even with Good Data In Statistics 101, we learn that correlation does not imply causation. Truly understanding this is one of the trickiest challenges across all disciplines. Let’s start with a question: Does drinking coffee cause better exam performance? You might run a survey and find that students who drink more coffee tend to score higher. Great! Does this mean coffee helps you score better? Not so fast. What if more studious students are both more likely to drink coffee and more likely to study hard? In that case, it is not the coffee. It is their study habits. Or what if students drink coffee because they are stressed from cramming, and that…
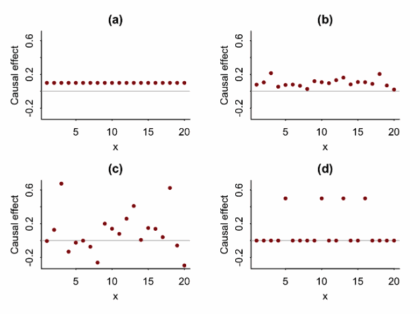
More than averages: using causal quartets to illustrate variability
Article Title: Causal Quartets: Different Ways to Attain the Same Average Treatment Effects [DOI:10.1080/00031305.2023.2267597]Authors & Year: A. Gelman, J. Hullman, and L. Kennedy (2023)Journal: The American StatisticianReview Prepared by Peter A. Gao Causal inference research commonly focuses on estimation of average treatment effects: In a target population, what is the difference in mean outcomes between individuals who receive the treatment and individuals who receive a control? For example, imagine an experiment investigating whether limiting daily phone usage improves academic performance among high school students. Subjects are randomly sorted into a treatment group (limited to one hour of phone time daily) or a control group (unrestricted) and over the course of a semester, their academic performance is measured using exams. In this case, the average treatment effect is simply the average exam score of the treated students minus the average score of the control students. If this effect is large and…
Causal Inference and Social Networks: How to Quantify the Effects of our Peers
“If all of your friends jumped off a cliff, would you jump too?” While this comeback may be just an annoying retort to many teenagers, it presents an interesting question – what is the effect of social influence? This is what Ogburn, Sofrygin, Diaz, and van der Laan explore in their paper, “Causal Inference for Social Network Data”. More specifically, they are interested in developing methods to estimate causal effects in social networks and applying this to data from the Framingham Heart Study.
Pinpointing Causality across Time and Geography: Uncovering the Relationship between Airstrikes and Insurgent Violence in Iraq
“Correlation is not causation”, as the saying goes, yet sometimes it can be, if certain assumptions are met. Describing those assumptions and developing methods to estimate causal effects, not just correlations, is the central concern of the causal inference field. Broadly speaking, causal inference seeks to measure the effect of a treatment on an outcome. This treatment can be an actual medicine or something more abstract like a policy. Much of the literature in this space focuses on relatively simple treatments/outcomes and uses data which doesn’t exhibit much dependency. As an example, clinicians often want to measure the effect of a binary treatment (received the drug or not) on a binary outcome (developed the disease or not). The data used to answer such questions is typically patient-level data where the patients are assumed to be independent from each other. To be clear, these simple setups are enormously useful and describe commonplace causal questions.
Determining the best way to route drivers for ridesharing via reinforcement learning
Companies often want to test the impact of one design decision over another, for example Google might want to compare the current ranking of search results (version A) with an alternative ranking (version B) and evaluate how the modification would affect users’ decisions and click behavior. An experiment to determine this impact on users is known as an A/B test, and many methods have been designed to measure the ‘treatment’ effect of the proposed change. However, these classical methods typically assume that changing one person’s treatment will not affect others (known as the Stable Unit Treatment Value Assumption or SUTVA). In the Google example, this is typically a valid assumption—showing one user different search results shouldn’t impact another user’s click behavior. But in some situations, SUTVA is violated, and new methods must be introduced to properly measure the effect of design changes.